Revisiting a PDF page counting script
A couple of years back, I created a bash script to count PDF pages across subfolders. Here's how it looks when run on my folder of Apple manuals:
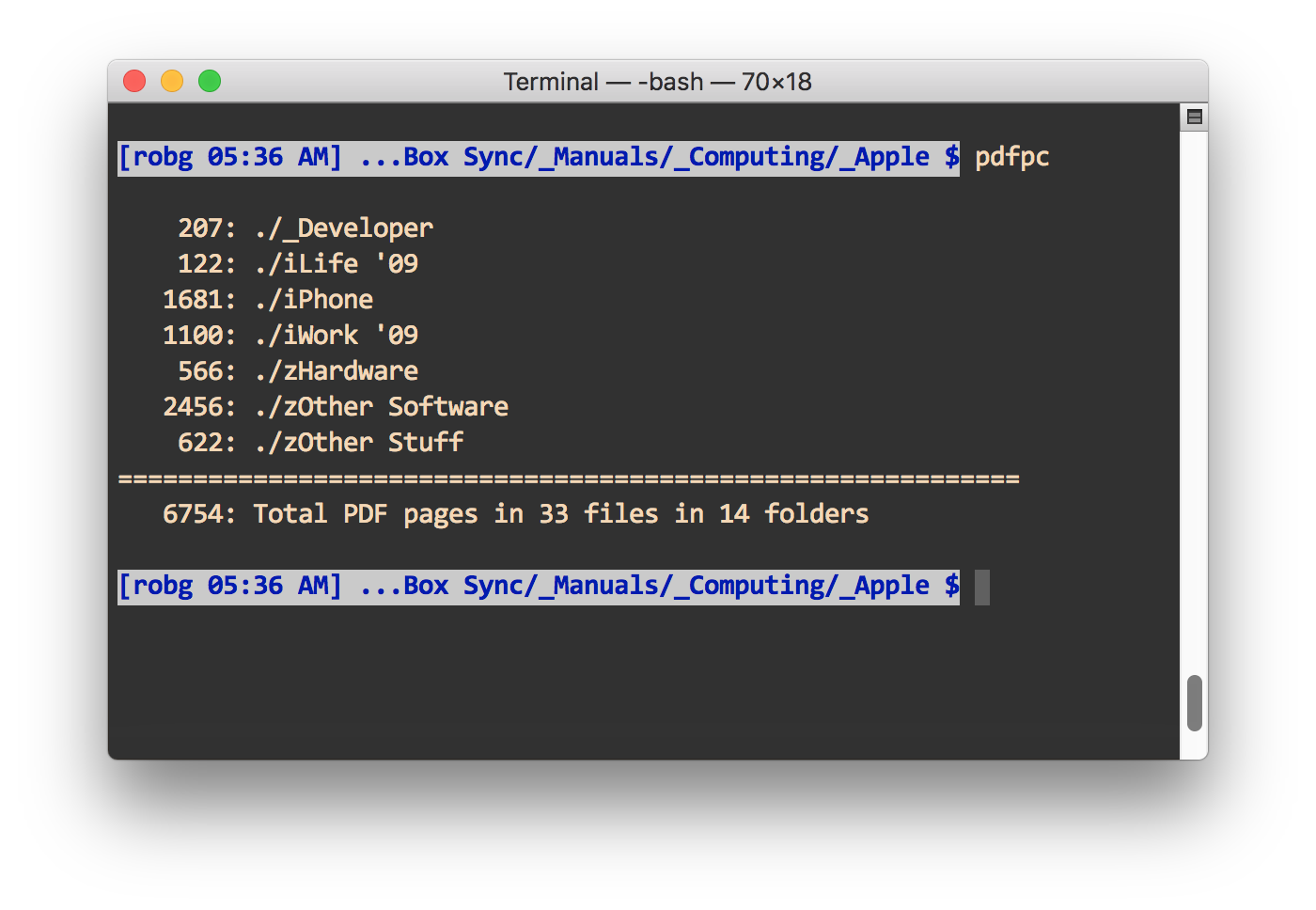
I use this script on the top-level folder where I save all my Fujitsu ScanSnap iX500 scans. Why? Partly because I'm a geek, and partly because it helps me identify folders I might not need to keep on their own—if there are only a few pages in a folder, I'll generally try to consolidate its contents into another lightly-used folder.
The script I originally wrote worked fine, and still works fine—sort of. When I originally wrote about it, I said…
I feared this would be incredibly slow, but it only took about 40 seconds to traverse a folder structure with about a gigabyte of PDFs in about 1,500 files spread across 160 subfolders, and totalling 5,306 PDF pages.
That was then, this is now: With 12,173 pages of PDFs spread across 4,475 files in 295 folders, the script takes over two minutes to run—155 seconds, to be precise. That's not anywhere near acceptable, so I set out to see if I could improve my script's performance.
In the end, I succeeded—though it was more of a "we succeeded" thing, as my friend James (who uses a very similar scan-and-file setup) and I went back-and-forth with changes over a couple days. The new script takes just over 10 seconds to count pages in the same set of files. (It's even more impressive if the files aren't so spread out—my eBooks/Manuals folder has over 12,000 pages, too, but in just 139 files in 43 folders…the script runs in just over a second.)
Where'd the speed boost come from? One simple change that seems obvious in hindsight, but I was amazed actually worked…
