A couple of years back, I created a bash script to count PDF pages across subfolders. Here's how it looks when run on my folder of Apple manuals:
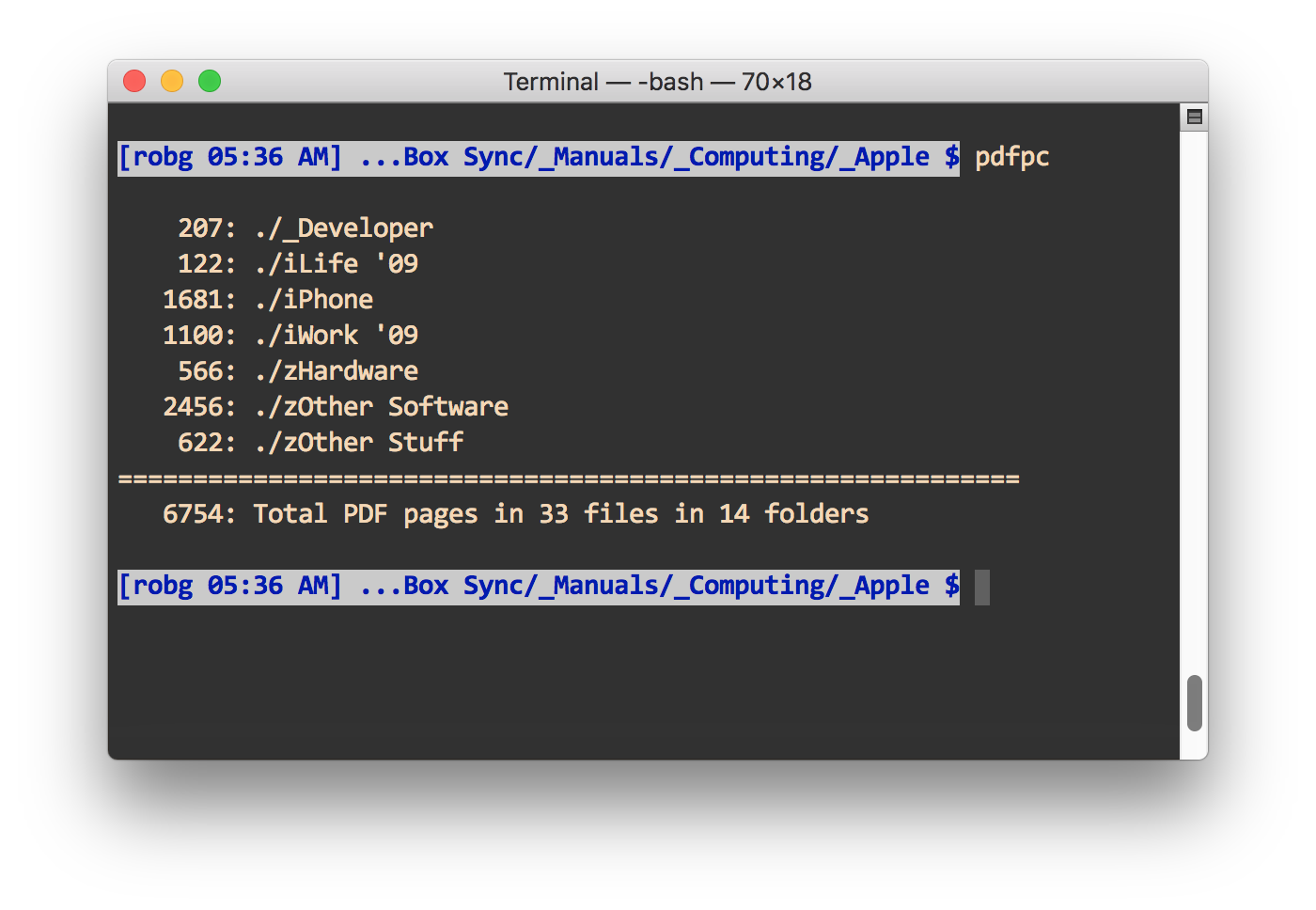
I use this script on the top-level folder where I save all my Fujitsu ScanSnap iX500 scans. Why? Partly because I'm a geek, and partly because it helps me identify folders I might not need to keep on their own—if there are only a few pages in a folder, I'll generally try to consolidate its contents into another lightly-used folder.
The script I originally wrote worked fine, and still works fine—sort of. When I originally wrote about it, I said…
I feared this would be incredibly slow, but it only took about 40 seconds to traverse a folder structure with about a gigabyte of PDFs in about 1,500 files spread across 160 subfolders, and totalling 5,306 PDF pages.
That was then, this is now: With 12,173 pages of PDFs spread across 4,475 files in 295 folders, the script takes over two minutes to run—155 seconds, to be precise. That's not anywhere near acceptable, so I set out to see if I could improve my script's performance.
In the end, I succeeded—though it was more of a "we succeeded" thing, as my friend James (who uses a very similar scan-and-file setup) and I went back-and-forth with changes over a couple days. The new script takes just over 10 seconds to count pages in the same set of files. (It's even more impressive if the files aren't so spread out—my eBooks/Manuals folder has over 12,000 pages, too, but in just 139 files in 43 folders…the script runs in just over a second.)
Where'd the speed boost come from? One simple change that seems obvious in hindsight, but I was amazed actually worked…
The really slow part of the old script was that it needed to get the mdls output for each PDF file in every folder. Originally that was done with this line:
pageCount=$(mdls ${myFiles[j]} | grep kMDItemNumberOfPages | awk -F'= ' '{print $2}')
This was inside a while loop that processed every PDF file in the current folder; that loop was inside a larger while loop that traversed every folder. The script was making over 12,000 calls to mdls, one file at a time. We first cleaned up that command, directly reading mdls for the page count value instead of using grep and awk on the entire output:
pageCount=$(mdls -name kMDItemNumberOfPages ${myFiles[j]} | cut -d' ' -f3)
This did save some time, but only about 15 seconds. Next we tried using a hash file in each folder, based on the output of ls -al *.pdf. We'd name the file the actual hash value (starting with .hash_, to make it invisible), and store the total page count for a given folder in that hash file. The initial run wouldn't be any quicker, but subsequent runs would be very fast: We'd calculate a new hash, and if it was the same as the saved hash file's name (i.e. no changes in the folder), we'd just read the hash file's saved page count.
This worked, but writing—and checking and managing—an extra file (even though it was invisible in Finder) in every folder seemed like a hacky solution. Then I had a random thought…I wondered if you could read the mdls values for an entire group of files at once. And it turns out you can:
$ mdls -name kMDItemNumberOfPages *.pdf | cut -d' ' -f3
5
30
4
2
14
etc...
Those are the page counts for all PDFs in the current directory. Bingo! No more iterating through each and every file in each and every folder. Instead, the script just needs to run that command once in each folder, place the results in a variable, then sum (through an ugly-looking echo command that I found buried in a Stack Overflow thread) the retrieved page counts.
Doing it this way, the code dropped from 61 lines to 20—there are no more nested while/if structures, as all the work can be done with a single for loop and a single if statement. I added a couple variables to count the files and folders (gratuitous statistics!) and it was done:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | #!/bin/bash saveIFS=$IFS IFS=$'\n' # Useless but fun statistics for grand total line myDirCount=$(find . -type d | wc -l) myFileCount=$(find ./ -name "*.pdf" | wc -l) echo "" grandtotalPages=0 myFolders=$(find . -type d) for dirsToSearch in $myFolders; do # Need the escaped path for the bash commands adjPath=$(printf '%q' "$dirsToSearch") if compgen -G "$adjPath/*.pdf" > /dev/null; then # We have some PDFs # Grab the mdls output for the page count for every file at once, then add it up. allPages=$(mdls -name kMDItemNumberOfPages $adjPath/*.pdf | cut -d' ' -f3) subtotalPages=$(echo $(( ${allPages//$'\n'/+} ))) # Update the grand total grandtotalPages=$((grandtotalPages + subtotalPages)) # Print the results printf "% 7d: %s\n" $subtotalPages $dirsToSearch fi done printf '=%.0s' {1..60} printf "\n% 7d: Total PDF pages in %d files in %d folders\n" $grandtotalPages $myFileCount $myDirCount IFS=$saveIFS |
This is a very niche thing, but if you're looking for a fast way to process mdls data—obviously there's a lot more there than just PDF page counts—on a slew of files, knowing that you can read it all at once may prove helpful.