Revisting old-school stock quotes
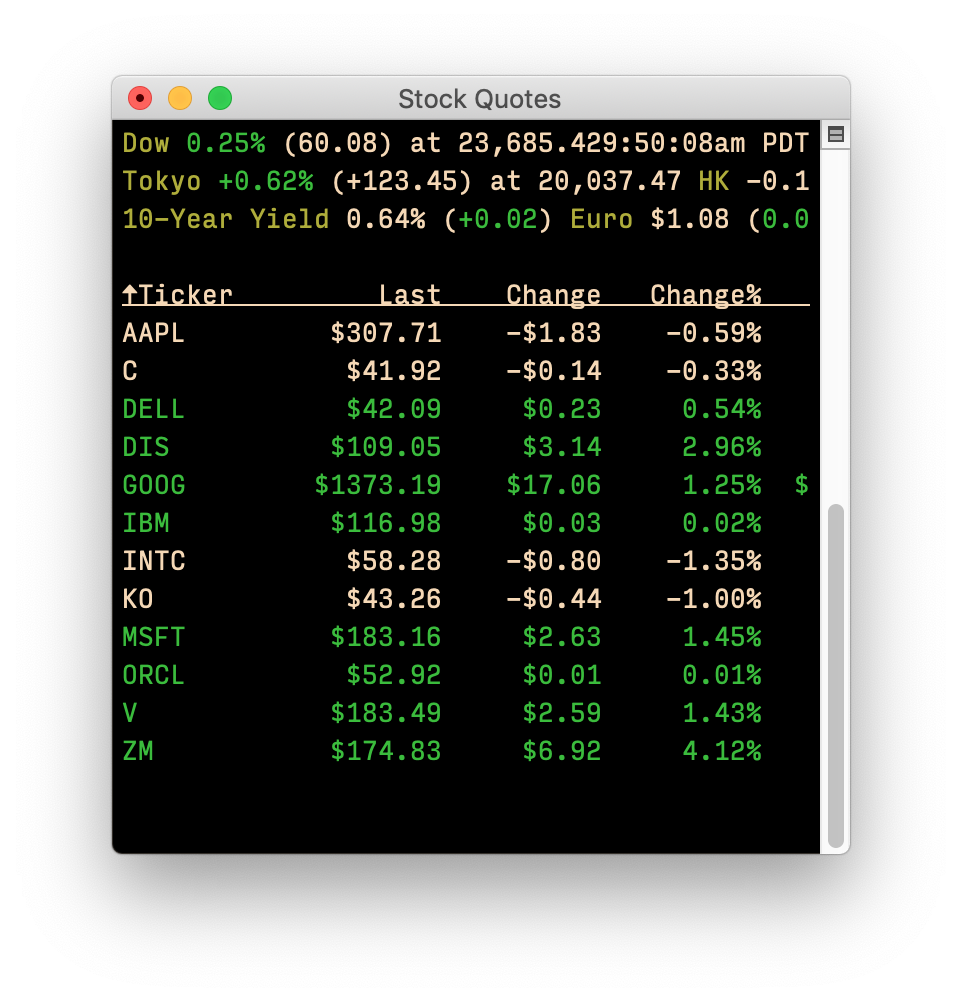 Back in 2020, I explained how to use Terminal to display stock quotes. Once set up, it looks something like the image at right, though that's a four-year old screenshot, so the prices are way off!
Back in 2020, I explained how to use Terminal to display stock quotes. Once set up, it looks something like the image at right, though that's a four-year old screenshot, so the prices are way off!
In a follow-up post, I showed how to quickly chart any of the stocks in your list. I've moved to a new Mac since then, which means (as always for me with a new Mac), I set it up from scratch.
Sometimes not everything makes the cut for the new Mac; in this case, my Terminal quotes were one of the things that didn't make the cut.
But I recently decided I wanted them back, and the good news is that it's gotten a bit simpler in four years since I last wrote about this. And I took the time to improve the stock charting macro, too.
Read on if you're interested in geeky Terminal stock quotes…
 As much as I rely on our own
As much as I rely on our own